Talk:Circular Error Probable
I think the section on "Systematic Accuracy Bias" misses the point.
Consider two experiments.
(1) Sight weapon then Shoot 10 groups
(2) (a)Sight weapon then shoot group (b) do (a) 10 times
Method (1) has accuracy bias but method (2) does not.
Herb (talk) 18:53, 1 June 2015 (EDT)
- Here's my take: "Systematic accuracy bias" on this page means that the true center of the shot distribution is different from the point of aim (POA). The CEP-radius can then be calculated around two possible centers - either a) around the known POA, or b) around the unknown true distribution mean.
- a) takes into account systematic accuracy bias because the further away the true center of the shot distribution is from the POA, the larger the CEP around the POA becomes, holding distribution spread constant. b) does not take into account systematic accuracy bias because CEP does not vary with increasing distance from true group center to POA, holding distribution spread constant.
- In a) only distribution spread (or the full covariance matrix) has to be estimated from observed data, in b) the true center also has to be estimated.
- Any help in getting this issue better across is highly appreciated.
RE: The CEP-radius can then be calculated around two possible centers - either a) around the known POA, or b) around the unknown true distribution mean. from above.
The wiki in general uses a third point, the \(\overline{POI_{sample}}\), from which the measurements are calculated. It is the only point for which an actual measurement can be obtained from the sample of shots.
All in all semantics, but the wiki ought to be consistent unless there is some reason to deviate. If a deviation is required, then it should be explicitly stated.
Herb (talk) 16:34, 2 June 2015 (EDT)
- True, we can sample the POI, but there exists a true POI. We can use the true POI in our models regardless of whether we can sample or estimate it in practice. That's true of many of the variables and measures discussed throughout the site: There is a true value we may (or may not) be able to estimate, and then there are sample values (which may be used to estimate the true value). David (talk) 16:39, 2 June 2015 (EDT)
- David, I fully agree. My explanation was concerned with the true CEP - which is unfortunately lacking its own distinct symbol. The true CEP has an estimator \(\widehat{CEP}\) which uses \(\overline{POI_{sample}}\) as an estimate for the true group center (when systematic accuracy bias is not taken into account).
- How about using * as a superscript to denote the value for the population? So \(CEP^*\) for the population \(CEP\) measure taken from the true \(COI^*\)? I had a mental fart using \(\overline{POI_{sample}}\). It is already well defined in the literature as \(COI\). So \(COI\) (sample of shots) as opposed to \(COI^*\) (the population of shots).
- I never doubted that the population values existed it is just that the typical frame of reference is the \(COI\) (from the shot sample), not \(COI^*\) (the population of shots). Since you hop around in a wiki, I think that the wiki has to be more diligent in using a consistent nomenclature than you might use in a book which is read more linearly.
- So I would change first paragraph to be:
- Rayleigh: When the true center of the shot distribution, \(COI^*\), coincides with the true point of aim, \(POA^*\), then radial error around the \(COI^*\) for a bivariate distribution with the horizontal and vertical measurements uncorrelated, independent, and normally distributed with equal variances, follows a Rayleigh distribution. This distribution is described in the Closed Form Precision section. In three dimensions (spherical error probable, SEP), the radial error follows a Maxwell-Boltzmann distribution which is the basis for the ideal gas laws in chemistry.
- So * denotes the true ("population") value, and the absence of a * denotes the sample value? I thought it usually went the other way around – i.e., asterisk/hash/bar for sample value, but as long as it's consistent here I'll live. So you're proposing:
- Markup variables with "*" whenever they are a true value and the variable may also denote a sample value. (Therefore, there would be no POA* because there is no such thing as a sample POA, right?)
- Use "COI" (Center of Impact) everywhere instead of "POI" (Point of Impact).
- David (talk) 17:16, 3 June 2015 (EDT)
- So * denotes the true ("population") value, and the absence of a * denotes the sample value? I thought it usually went the other way around – i.e., asterisk/hash/bar for sample value, but as long as it's consistent here I'll live. So you're proposing:
- No, I'm proposing "*" just for some variables (measures):
- \(COI\) - center of impact measured for n shots on a target
- \(COI^*\) - "true" center of impact, ie if COI could be measured for an infinite number of shots (sighting error essentially).
- \(POA\) - position where you were really aiming for a shot
- \(\overline{POA}\) - position where you were really aiming averaged over one target
- \(\overline{POA}_m\) - position where you were really aiming averaged over m targets
- \(POA^*\) - "true" point of aim, ie as if measured for an infinite number of shots
- The point here is process control. For instance if you could pluck out \(\sigma_{POA}\) then you could work to improve that aspect of your shooting. As it is \(\sigma_{POA}^2\) is buried in \(\sigma_{System}^2\) and virtually impossible to detect - if you're shooting close to decently. Think of a bad check weld when using sights.
- My thought was that \(\overline{COI}_m\) would be averrage COI over \(m\) targets.
- On second though how about \(\overline{COI}_\infty\) instead of \(COI^*\)??
- No, I'm proposing "*" just for some variables (measures):
- For CEP calculation that takes into account systematic accuracy, the main point about POA is that it needs to be known, i.e. there is no uncertainty or need for estimation. Therefore "POA" has the meaning of "this is where the bullets should go". In the literature on this (eg. Grubbs), POA is typically taken as coordinates (0,0). I agree that "POA" can have a different meaning along the lines of "this is where the sight was actually pointing", but as you say, it's not clear how that could be estimated independently.
- In the above suggested paragraph uncorrelated and equal variances are actually probably the most redundant, but I think it necessary to make both points clearly. In other words, I'm sure only about 1% of the readers would understand why the two are redundant. Also "uncorrelated" and "independent" are two different concepts.
Herb (talk) 12:43, 3 June 2015 (EDT)
- In the above suggested paragraph uncorrelated and equal variances are actually probably the most redundant, but I think it necessary to make both points clearly. In other words, I'm sure only about 1% of the readers would understand why the two are redundant. Also "uncorrelated" and "independent" are two different concepts.
- I have. Look at the figure from the wikipedia article Correlation and dependence. The Rayleigh Distribution is shown in top row center. All the shot patterns on the bottom row have 0 correlation. The shots are obviously not independent in H-V. The hollow circle would have equal variance too. Obviously a hollow circle is a contrived example, but paying attention to such examples is the way to keep statistics from biting your ass. :-(
Herb (talk) 20:44, 3 June 2015 (EDT)
- I have. Look at the figure from the wikipedia article Correlation and dependence. The Rayleigh Distribution is shown in top row center. All the shot patterns on the bottom row have 0 correlation. The shots are obviously not independent in H-V. The hollow circle would have equal variance too. Obviously a hollow circle is a contrived example, but paying attention to such examples is the way to keep statistics from biting your ass. :-(
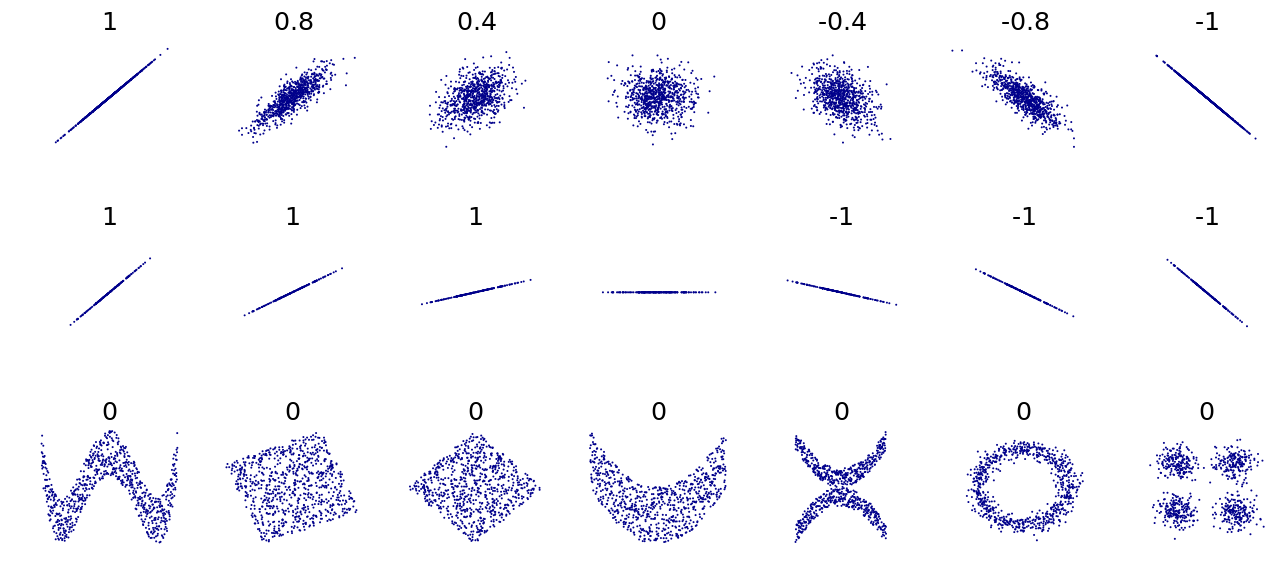{kind=link}
- For the Rayleigh model, we are assuming bivariate normality of h and v coordinates. For bivariate normal variables, "independence" and "0 correlation" are equivalent. "0 correlation" and "equal variances" are not redundant as you can have 0 correlation with unequal variances as well as correlated variables with equal variances.
Correlation and Variances
If the variances are not equal you get an ellipse.
Correlation is based on probabilistic expectation, not because of an causality interaction between the two variables ( h and v). So if the shot pattern is an ellipse instead of a circle there will be correlation. Think of fitting a straight line to the data with linear least squares. There is a correlation of the data to the long axis of the ellipse. The rub here is that correlation does not prove causation. ie. just because we find an ellipse doesn't mean that h = Function(v) or that v = Function(h).
Herb (talk) 11:14, 4 June 2015 (EDT)
- There are elliptical shot patterns with 0 correlation. This is the case when the ellipse axes are parallel to the h and v axes like this: http://imgur.com/g8W1MHH Only when the ellipse is slanted at an angle != 0 there is correlation.
- Thanks, I'll have to chew on that a while. I was thinking that "correlation" would be about long axis of ellipse. In other words if you rotated an elliptical shot group about the COI of the ellipse that the internal correlation wouldn't change.
- I'm in the deep end of the pool here. If V = F(H) then the error for some point i would be measured along line parallel to V axis. But if H and V are independent then don't you measure from error from point "i" perpendicular to fit line?. That is to say that the perpendicular distance from shot i to the long axis of the ellipse wouldn't change with the rotation of the ellipse about its center.
- Just to be clear I'm thinking of the shot pattern on a transparent sheet with a pin through COI. So you're rotating the whole shot pattern relative to H,V axes, not the ellipse over the shot pattern.
- Here is an link to an image for "ordinary" least squares where Y is dependent on X. In other words X is known perfectly and all the error is in the Y measurement. If you rotate the points about their center then obviously the residuals (in green) change.
- http://en.wikipedia.org/wiki/File:Linear_least_squares_example2.svg
- Herb (talk) 18:41, 4 June 2015 (EDT)
{kind=link}
Dependency and Correlation
H and V are both \(\mathcal{N}(0,\,\sigma^2)\)
shoot a target.
Thus there is no correlation. ie, no straight line to fit with linear least squares. There is just a random radial pattern.
I calculate CEP(50) and make a circular steel plate that big. Say the plate is 10 inches.
I put the center of the plate over the center of the target and shoot. I take plate off and look at holes in target The holes form an annulus. There is no linear correlation because there is no line upon which the data bunches.
But given H=1, is it possible that V=2? No that shot would have hit the steel plate and was stopped. So H and V are not independent now. In other words, can you tell which target was shot with the plate and which without?
Yes this shot pattern seems unrealistic in the real world, but that isn't how statistics works. We can only use assumptions that we started with. For example given the starting normal distributions above, let's assume that I'm shooting a handgun. I ask the computer "What is the probability of my pistol shot going 5 miles high along the vertical axis?" The computer will spit out a number. With no external ballistics in probability model there is nothing to tell computer that such a situation is impossible.
See wikipedia article Correlation and dependence
Herb (talk) 11:14, 4 June 2015 (EDT)
- Regarding the earlier question: We know that in general correlation and dependence are not the same thing. But as Armadillo noted, it is redundant to say we're using a bivariate normal with independent and uncorrelated axes. David (talk) 12:26, 4 June 2015 (EDT)
- ??!??
- Given:
- * \(h \sim \mathcal{N}(0,\,\sigma^2)\)
- * \(v \sim \mathcal{N}(0,\,4\sigma^2)\)
- * \( v \neq F(h)\)
- then h and v are correlated along long v axis even though they are independent. They are correlated because the figure is an ellipse. Correlated just means that there is a "significant" linear least squares line. Mathematical correlation does not mean causation.
Herb (talk) 16:10, 4 June 2015 (EDT)
- h and v need to be jointly normally distributed (= bivariate normal), not just marginally, see http://en.wikipedia.org/wiki/Multivariate_normal_distribution#Correlations_and_independence For the radial error to be Rayleigh distributed, we need to assume joint normality.
- Also note that a joint elliptical distribution does not automatically imply correlation. If the major and minor axes of the ellipse are parallel to the h and v axes, the correlation is 0, see: http://imgur.com/g8W1MHH Only when the ellipse is slanted at an angle != 0 there is correlation.
- The technique is Total Least Squares. Here is the plot showing residuals. The gist is that since H and V are independent then there is error in each. Measuring the distance to the fit line thus assume that H and V errors are equal. I have no idea what the effect of using this method would be for the bivariate normal distribution.
Herb (talk) 00:40, 5 June 2015 (EDT)
- The technique is Total Least Squares. Here is the plot showing residuals. The gist is that since H and V are independent then there is error in each. Measuring the distance to the fit line thus assume that H and V errors are equal. I have no idea what the effect of using this method would be for the bivariate normal distribution.
{kind=link}
- Using Total least squares wouldn't change the fact that I have been wrong. The correlation is based on \(\Delta(v)/\Delta(h)\) which be undefined along either axis.
Simplex
Funny, none of these methods seem to analyze the problem like I'd approach it. To me it is if the target is on a ball joint at the COI. So you're aiming at a center point, but the holes are being punched in a target at an 3-d angle.
To start consider target mounted "perpendicularly" to the line of fire like at a rifle range. If the bottom of the target has a hinge parallel to the horizontal axis, then you can tilt the target back. You get elliptical groups with the long axis oriented along the vertical axis of the "recording" target. If the hinge were on the left you could get elliptical groups in horizontal direction. Thus a target on a ball joint would be able to make any shape group.
The problem is then to find the 3 angles that minimized the error when the holes are projected back to a "perpendicular" target. I'd use a simplex to explore the angles. It would no doubt be "lumpy" since the sample size is assumed to be small. So you'd have to start the simplex from a couple of different angle sets to be sure it converged to the same 3 angles.
I doubt that the model would have an exact solution because the normal errors on the "perpendicular" target change when projected onto the tilted target. I think more shots would just mean that the simplex would converge faster and more assuredly to the same 3 angles. It would also be nasty because the COI would move when the shots were projected back to the "perpendicular" target. Thus error has two parts, moving COI and about new COI.
Nutty ideas like this are probably why I was better off as an analytical chemist instead of a statistician. ;-)